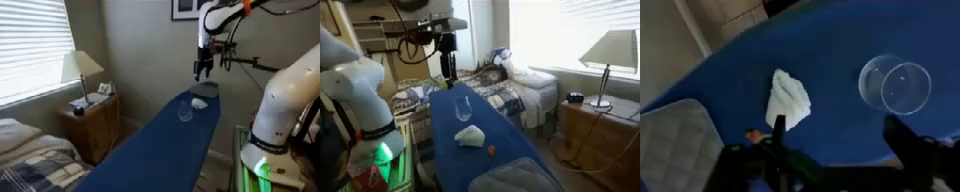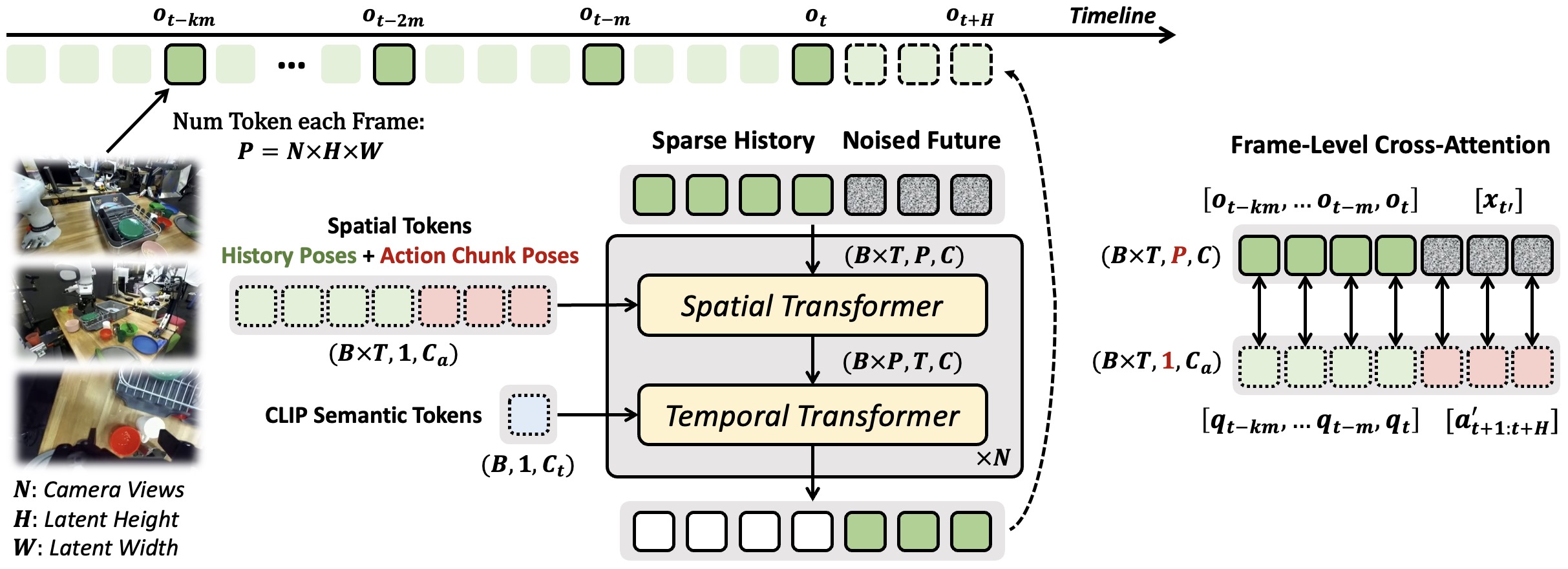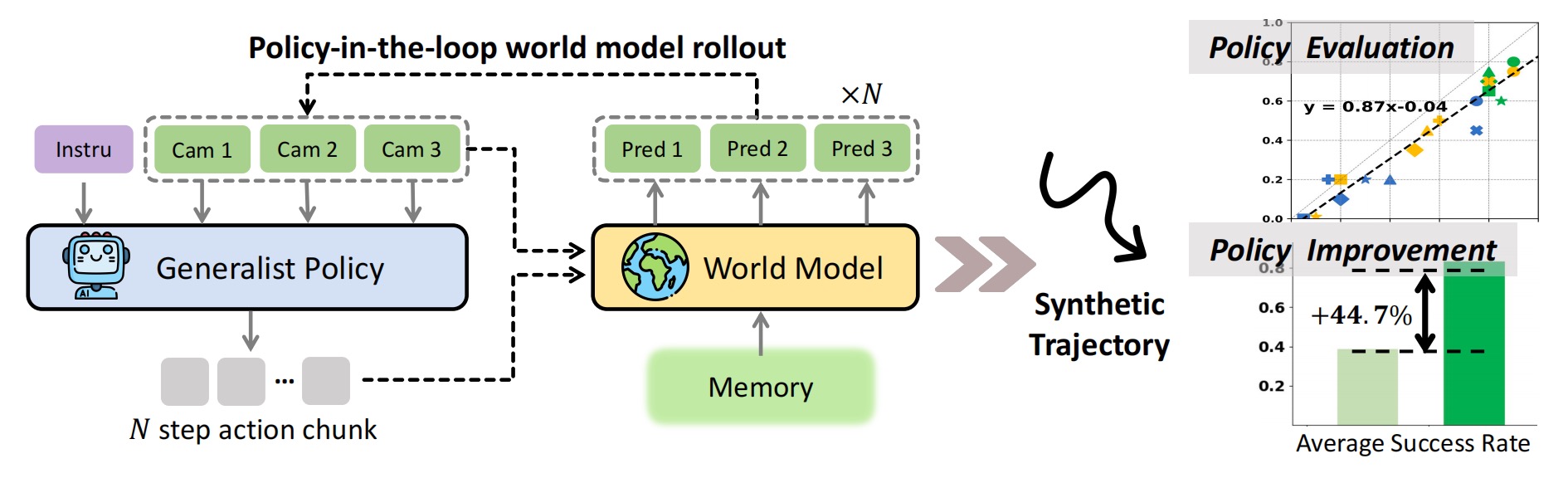
Ctrl-World is designed for policy-in-the-loop rollouts with generalist robot policies. It generates joint multi-view predictions (including wrist views), enforces fine-grained action control via frame-level conditioning, and sustains coherent long-horizon dynamics through pose-conditioned memory retrieval. Together, these components enable (1) accurate evaluation of policy instruction-following ability via imagination, and (2) targeted policy improvement on previously unseen instructions.